
I just built this handy dashboard on Tableau Public. Unfortunately, it does not seem to work here, so you can better examine it directly on Tableau for now.
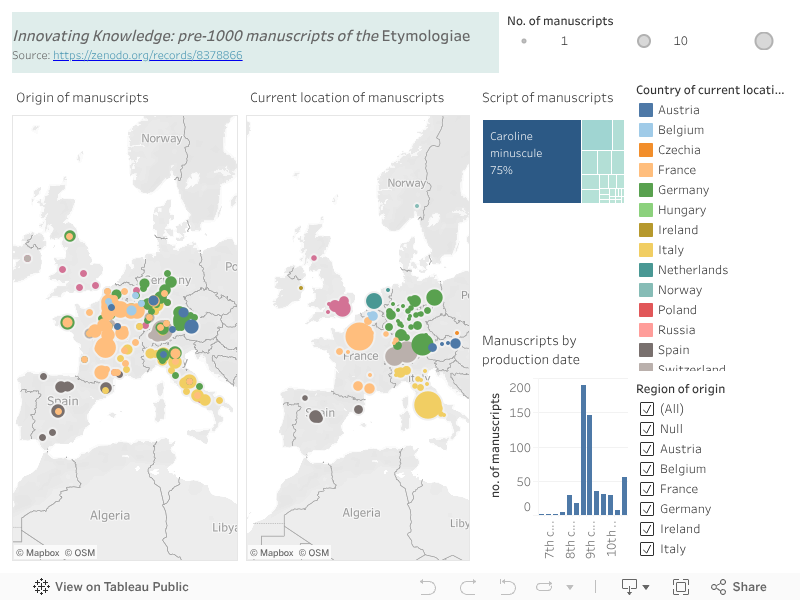
I just built this handy dashboard on Tableau Public. Unfortunately, it does not seem to work here, so you can better examine it directly on Tableau for now.

A while ago, I was invited by the Fernuniversität Hagen to present on a topic close to my heart: online manuscript databases. I became interested in this topic when I started to build my own manuscript database as a part of the Innovating Knowledge project in 2018. Back then, I thought manuscript databases are cool, important, and the right way to go for small postdoc projects like mine – oh boy, how wrong was I!
In the five years since the beginning of my project (and in the three years since the launch of the first version of my database) I have changed my opinion quite a lot. As I learned a lot about the complex lives (and inevitable deaths) of manuscript databases, I became significantly more skeptical about the long-term value of what I have termed SDMMPs (small digital manuscript metadata projects), especially as long as there is no overreaching infrastructure or community supporting them. In 2021, I started to map the budding ecosystem of SDMMPs to learn more about their life and death cycles and understand what is out there and what the prognosis is for the long term. I presented my thoughts on the SDMMPs at the On the Way to the Future of Digital Manuscript Studies workshop in November 2021. At the time, I could account for more than 50 manuscript database projects (including mine). I have continued to survey the landscape since: I am currently aware of more than 70 projects. Their number continues to grow and there is no indication that the manuscript database trend abating, quite the contrary!

My own experience with building a small manuscript database and the discussions I have had with my colleagues planning to start a database project or already working towards a manuscript database as a part of a funded research project made me realize that while databases are popular and certainly useful for specific purposes, many manuscript scholars and historians developing them are ill-equipped to bring them to life and, more importantly, make them last past the project funding end. I certainly made many mistakes on my journey.
The mistakes, the conversations, my own journey made me distill some of the most important lessons I learned while building the Innovating Knowledge database into a videopresentation for the Hagener Forschunsdialog. I upload the video here for those who may be interested in the subject and think they may benefit from advice of a fellow medievalist. Enjoy and let me know whether you find the 10 and 1/2 lessons for manuscript database building useful!
When I began my Innovating Knowledge project more than four years ago, one of my intentions was to map how manuscripts of the Etymologiae attracted interpolations and other ‘edits’ in the early Middle Ages. As the Etymologies is an encyclopaedia, and moreover one that its author never completed, it is no surprise that it acted as a scaffolding for the accumulation of new ‘useful’ information. Early in the project, I therefore decided on a system of recording what I termed innovative features (or innovations for short) that would later allow me to project them as a network. For the purpose of my project, I defined an innovative feature as:
In this network, manuscripts transmitting the Etymologiae represent nodes and innovations that they contain represent edges connecting manuscripts that share a particular feature. By plotting the network, I hoped to not only see which innovative features were widespread (and which not) and which manuscripts combined many different features, but also whether the patterns of sharing can provide us with a meaningful picture about the diffusion of certain innovations. It was evident to me from early on that while some of the features I was interested in spread genealogically, that is by copying from an exemplar like texts, others, perhaps the majority, circulated due to other processes. As a result, I reasoned, it is unlikely that the presence or absence of certain innovative features could be used to reconstruct a stemma of the early textual tradition of the Etymologiae (but some would emerge as being highly significant and reliable in this regard). Thus, a network could be constructed as a lighter alternative to a stemma and could serve as the first step towards discerning those innovative features that are indicative of a genealogical relationship from those that are not.
As the project progressed and my datasheet filled in, it became clear to me that my initial idea of a network of innovations was somewhat naïve and that my data exhibits typical problems that make plotting of a network problematic and biased. In particular, I was afraid I would end with the usual hairball graph that has limited added value. I also understood that I am likely missing many innovations altogether and many witnesses of identified innovations. Nevertheless, I thought that even though I could not use the network visualization that I imagined as I had originally intended, I could at least try to construct the network I had in mind as a kind of an explorative experiment. The result was a surprise in a good sense as it turned out that the graph that could be constructed from my data using the principles outlined above does work better than I thought.
The following network graph was plotted in Gephi using Fruchterman-Reingold algorithm. I performed some additional manual adjustments to minimize overlap of unrelated clusters and give it a cleaner look.

The network graph you see here includes 279 manuscripts (nodes) transmitting the Etymologiae that share an innovation with at least one other known manuscript. This is not a small number given that I have been able to identify 485 early medieval manuscripts transmitting the Etymologiae. Even though the manuscripts displayed in the network above also include 81 post-1000 manuscripts included because of their relevance to the picture, this still means that 198 manuscripts that are part of my early medieval corpus, or more than 40% of identified pre-1000 codices transmitting the Etymologiae, include at least one innovative feature also appearing in another known manuscript. That’s a useful ratio to begin with! Importantly, these are not all (or all early medieval) manuscripts of the Etymologiae featuring innovations, as this count does not include manuscripts transmitting innovations confined to a single codex, or such that have been so far identified in only a single manuscript, albeit they feature in more. Thus, we should reasonably assume that most of the early medieval copies of the Etymologiae, partial and full, contain some innovations.
The network graph above shows a total of 1042 shared innovations (edges). As can be gleaned from the graph, it is constituted by many isolated components which are not connected to other parts of the graph. These are instances of a particular innovative feature that appears in several manuscripts, while these manuscripts contain no other innovative features identified during my project. All in all, the graph I plotted using my imperfect data consists of 40 such components. Of these, 19 components, or almost half of all components in the graph, consist of only two manuscripts, i.e., I was able to identify only two manuscripts having a specific notable innovative feature. Seven more components consist of three or four manuscripts. These components are left uncoloured in the graph.
More than 40% of identified pre-1000 codices transmitting the Etymologiae include at least one innovative feature also appearing in another known manuscript
Many of the 14 larger components are also isolated. We can, therefore, say that the gathered data suggest that early medieval manuscripts transmitting the Etymologiae have a tendency of containing but a single innovation (rather than, say, two, four or six). There is a good explanation for this pattern. After all, most of the manuscripts in the graph above do not transmit the entire encyclopaedia in 20 books, but are rather partial witnesses in the form of handbooks, miscellanies, and collections transmitting a specific selection from the Etymologiae in a non-encyclopaedic setup. For example, the relatively large blue component on the bottom left side of the graph corresponds to the 15 known manuscripts transmitting separately parts of the third book of the Etymologiae dealing with music (Etym. III 15-23), known also as the Ars musica Isidori. The orange component on the bottom right side of the graph includes the nine identified witnesses of the shorter version of the so-called Collectio Unde, a patchwork collection of excerpts from books VI, VII, VIII, and IX.

Since the two textual entities do not overlap at all in their selection from the Etymologiae, it can be expected that they should appear isolated from each other in the graph. In theory, if a single manuscript transmitted both the Ars musica Isidori and the Collectio Unde, it would form a bridge between the two clusters. Indeed, this is the case with two manuscripts that connect three clusters into the second largest component of the graph consisting of 27 manuscripts.

The three clusters in question correspond to manuscripts transmitting a patchwork of excerpts from the Etymologiae dealing with the Church, its offices, and baptism known as De catholica ecclesia et eius ministris et de baptismatis officio (brown), those transmitting another similar collection known as the Collectio Sangermanensis (pink), and those transmitting a collection of excerpts on kinship called in some manuscripts Dicta Isidori (green). These, too, are examples of manuscripts in which only a selection from the entire Etymologiae circulated.
By far the most intriguing component in the network is the large component in the central and upper parts of the graph, which totals 102 manuscripts (i.e., about 36.5 % of all manuscripts included in the graph). This component is not notable only because of its large size, but also because it is the only component in which a significant overlap of clusters can be observed. Indeed, this component is assembled from 14 different coloured clusters (i.e., clusters consisting of at least 5 manuscripts). The most fully connected manuscript belonging to this large component is a member of four clusters, i.e., it contains four widely shared innovations. The largest component also incorporates the largest cluster of the graph (purple) consisting of thirty manuscripts in which two segments of De natura rerum are interpolated into the astronomical sections of the Etymologiae (Etym. III 51 and 53).
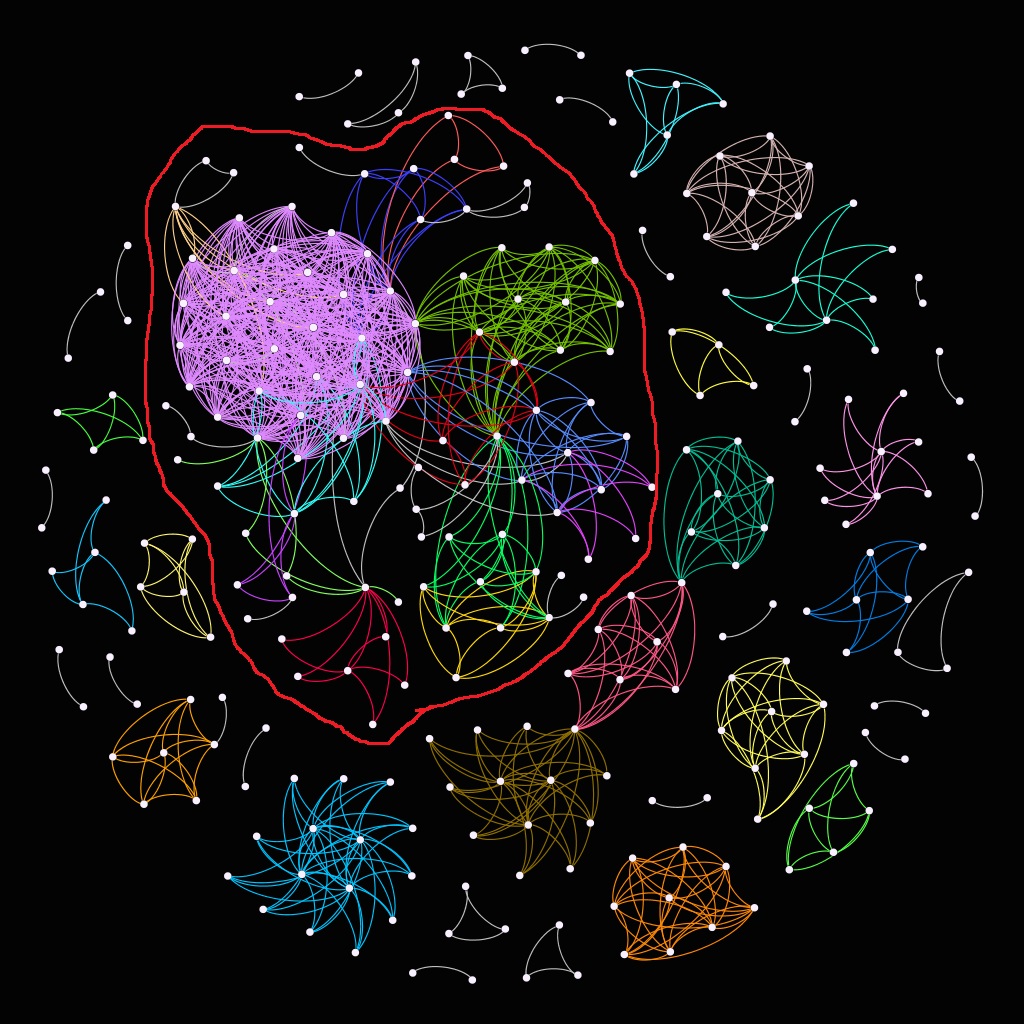
What is special about this component, apart from its size, is that unlike many of the smaller components, it does not consist of partial witnesses of the Etymologiae but of encyclopaedic copies featuring all twenty books of the work (or originally designed to include all books). The significant merging and blurring of clusters is a signal that these codices tended to acquire multiple innovations. For example, three of the eight manuscripts, in which book I lacks chapters 30-31 (blue in the center of the graph), also divide the Etymologiae into 17 rather than 20 books (dark purple in the center of the graph). All but two manuscripts that divided originally the first half of the Etymologiae into three books (red in the center of the component) have at least one other major innovation. Five of the eight manuscripts, in which the anonymous heresiological treatise Indiculus de haeresibus was interpolated into book VIII of the Etymologiae (brighter green at the bottom left of the largest component) also have the two segments of De natura rerum interpolated into book III (purple). Manuscripts containing a series of epigrams known as the Anthologia Isidoriana (bright green at the bottom right of the largest component) also tend to transmit an anonymous computistic treatise on the calculation of Easter (darker yellow at the bottom right of the largest component).
All of these overlaps raise questions. For example, we can ask ourselves, how would a largely or purely genealogical relationship be projected into a network graph like this and whether we see such a projection. We can start with imagining a hypothetical stemma in which a particular branch of witnesses characterized by a specific innovation (e.g., a textual interpolation) begets another branch, which is characterized by another innovation (e.g., a specific omission). In this scenario, all manuscripts having the latter innovation would also have the former. In a network projection following the rules outlined above, this hypothetical scenario would manifest as two clusters. All manuscripts which are member of a smaller cluster (specific omission) should also be members of a larger cluster (textual interpolation).
Indeed, we can note one cluster in the network graph constructed from my data about the Etymologiae that displays a high degree of such an overlap suggestive of a genealogical relationship between two innovations. This is the pale yellow cluster in the upper left side of the largest component that is almost fully merged with the large purple cluster corresponding to manuscripts with interpolated passages from the De natura rerum in book III. Some, but not a majority, of these manuscripts also received a set of astronomical diagrams with parallels in the De natura rerum. The uneven numbers may suggest that the diagrams represent an expansion of the older interpolated version featuring no diagrams.

I am planning to expand the network graph sketched above in the future as more manuscripts will be examined in detailed and the innovations they carry will be described and accounted for. Two of the most widespread innovations, the interpolations from the anonymous treatise on figures of speech De virtutibus et vitiis in book I and the inclusion of a TO-diagram into book XIV, moreover, are currently not included. Once the diagram becomes fuller, the next logical step is to investigate its network properties, for example the propensity towards innovations among the encyclopaedic copies of the Etymologiae (as opposed to the non-encycloapedic witnesses) or the degree of overlap between certain clusters (i.e., the degree of co-occurrence of certain innovative features). These could provide additional hints about one of the most intriguing questions of the diffusion of innovations in the copies of the Etymologiae: were they likely to be passed on vertically (by copying from a parent to an offspring), or was it more common that they traveled horizontally (e.g., as a result of contacts between neighbouring intellectual centers and movement of people)?
I stop here for now, but I promise more is coming on the diffusion of innovations and the use of network visualizations and analysis in the future.
PS: You may have noted that links from this blog post lead to the EtymoWiki on the Innovating Knowledge website, which is still empty. I hope to start adding entries describing some of the notable early medieval innovative features in the manuscripts of the Etymologiae soon.
It is official: the Innovating Knowledge project had successfully ended a few weeks ago! (A project bilan summing up what it achieved and what are some of its tastiest outputs will be published soon, I promise.)
For now, let me introduce you to the most significant project tool: a database of all surviving and identified manuscripts transmitting the text of the most important medieval Latin encyclopaedia, the Etymologies of Isidore of Seville. Until the 13th century, when Vincent of Beauvais published his Speculum Maius (The Great Mirror), the Etymologies was the only widely-used encyclopaedia in the Latin-writing world.
Why was this the case? Was it because of some intellectual deficit? The poverty of intellectual life? Or disinterest in knowledge?
Not at all!
Rather, prior to the great changes of the Renaissance of the Twelfth Century, people had a different idea about collecting and arranging knowledge. Instead of producing new encyclopaedias one after another, they took the one they already had – the Etymologies – and implemented any new ideas or changes they saw fitting directly into its text. That is why it acted as a sort of medieval Wikipedia – attracting “edits”. And that is why each copy of this encyclopaedia is a bit like a new version of Wikipedia. Taken together, they can be studied to assess the extent of innovation in the Middle Ages between 636 (when the Etymologies v1.0 was published) and approximately mid-13th century (when Vincent of Beauvais new encyclopaedia was put into circulation). For this, however, it is first necessary to identify and catalogue as many of the manuscripts of the Etymologies as possible, not a simple task, given how widespread and popular Isidore’s work was.
From the 1910s to the 1940s, German philologue G.E. Anspach tried to catalogue all the manuscripts containing the Etymologies or significant parts of this important text. Given the level of research techniques in the first half of the twentieth century, it may come as no surprise that he died in 1942 before completing this project, even as he could account for more than 1,100 medieval manuscripts! Of these, he estimated that almost 300 were produced before or around the year 1000. The Innovating Knowledge project followed in his footsteps. Boosted by the new digital technologies, we can now account for almost 500 pre-1000 manuscripts (and we have surely not found every single codex yet). The fact that we decided to build an online database rather than publish our findings as a printed catalogued or a similar resource means that we can continue to refine, correct, and expand our observations. And that is not the only advantage over a traditional publishing model.

We are currently preparing the release of v2.1 of the Innovating Knowledge database (v1.0 was released in April 2021 and v2.0 in October 2021). If all goes well, you can look forward to:
The database will also allow you to explore:
And of course, you can download the data powering the database, or various selections from it, directly through the database interface.
The entire Innovating Knowledge team hopes you will enjoy this fruit of our labour and find it useful. While we are working towards the release of the new version, you can also let us know if you think there is anything that needs to be improved further or if you like our database so far!
A three-day online conference organized by the Innovating Knowledge Project
21-23 October 2020
Online event
all times are in CET (time converter)
13.15 – 13.30 CET
Conference welcome
moderator: Hannah Busch (Huygens ING, KNAW, Amsterdam)
13.30 – 14.10 CET
14.20 – 15.00 CET
15.10 – 15.50 CET
Gustavo Fernández Riva (University of Heidelberg)
Networks of Shared Manuscript Transmission for Medieval European Vernacular Languages. Evaluating the Data and the Method
Andreas Kuczera (Akademie für Wissenschaften und Literatur, Mainz)/Martin Fechner (Berlin-Brandenburg Academy of Sciences and Humanities)
Aristoteles multimodal – with ediarum to the graph
Evina Steinová (Huygens ING, KNAW, Amsterdam)
Traveling Annotations: Network Analysis as a Tool to Study Glossing Networks in Carolingian Europe
17.00 – 18.00 CET
1on1 sessions for conference participants
moderator: Paolo Rossini (Erasmus University, Rotterdam)
10.00 – 10.15 CET
10.15 – 10.45 CET
10.55 – 11.25 CET
11.35 – 12.05 CET
Session introduction
Catherine Emerson (NUI Galway)
Textual and personal networks: The Chronique Abrégée in fifteenth-century Paris
Katharina Kaska (Austrian State Library)
Scribal and textual networks – collaboration and exchange in manuscripts and scriptoria
Katarzyna Anna Kapitan (University of Iceland)
A saga in a network and a network of a saga
Lunch break
moderator: Mariken Teeuwen (Huygens ING, KNAW, Amsterdam)
13.20 – 13.30 CET
13.30 – 14.10 CET
14.20 – 15.00 CET
15.10 – 15.50 CET
Session introduction
Dominique Stutzmann (IRHT Paris)/Louis Chevalier (IRHT Paris)
Books of hours as text compilations in the Low countries
Shari Boodts (Radboud University Nijmegen)/Iris Denis (Radboud University Nijmegen)
A sermon by any other name? The pseudo-Augustinian S. App. 121 and its medieval textual network
Richard Matthew Pollard (UQAM)
What do the Church Fathers, Scientific Fathers, and Military Fathers have in common?
16.00 – 16.50 CET
Round Table for conference participants
17.00 – 18.30 CET
Matteo Valleriani (Max Planck Institute for the History of Science/Technische Universität Berlin/Tel Aviv University)
Early Modern University Textbooks: How to Gain Hegemony
moderator: Gustavo Fernández Riva (University of Heidelberg)
10.00 – 10.15 CET
10.15 – 10.45 CET
10.55 – 11.25 CET
11.35 – 12.05 CET
Session introduction
Ina Serif (University of Basel)
From Networks of Texts to Networks of Genres? On the Classification of Texts in Compilations with a View towards Manuscript Transmission
Sara Steffen (University of Basel)
Audible Networks: Connecting Texts through Music in 16th-Century Swiss Printed Ballads
Jialong Liu (Leiden University)
Text Reuse in the Medieval Chinese Public Inscriptions (618-907)
Lunch break
moderator: Evina Steinová (Huygens ING, KNAW, Amsterdam)
13.20 – 13.30 CET
13.30 – 14.10 CET
14.20 – 15.00 CET
15.10 – 15.50 CET
Session introduction
Immo Warntjes (Trinity College Dublin)
Computistical objects and intellectual networks in the Carolingian age
Agata Paluch (Freie Universität Berlin)
Patterns of Knowledge Circulation in Early Modern East-Central Europe: Tracing Jewish Kabbalistic Textual Units in Multiple-Text Manuscripts
Elizabeth Archibald (Pittsburgh University)
Medieval Library Catalogues and Intellectual Networks
16.00 – 17.00 CET
17.00 – 17.30 CET
1on1 sessions for conference participants
Conference wrap-up
You can download the full programme as a PDF here.
For more information and to register as an attendee, contact Evina Steinova (evina.steinova@gmail.com)

Featured image: London, British Library, Harley 3941/2, fol. 177r: a little map of the world squeezed in the margin of the chapter De orbe (Etym. XIIII 2)
We have all been there. Whether in the middle of a busy day or during a lazy weekend, a burning question arose in your mind that Wikipedia cannot answer. What stone did Romans consider the best remedy for a toothache? How many trisyllabic metres there are in Latin poetry? Which heretic was it again who thought the Paradise is not a real physical place, but the Resurrection was real? What was the sixth Hebrew name of God according to St. Jerome? What was the name of that funny footwear women wore in Gallia last time Julius Caesar stopped by? You are 100 % sure these questions can be answered by the most celebrated Latin encyclopaedia of the Middle Ages (and thus of all times) – the Etymologiae of Isidore of Seville! All you need is to know where to find a copy, preferably an early medieval one, because there is nothing as calming and reassuring as reading your Isidore in Caroline minuscule. If you ever found yourself in this place, as I don’t doubt many of you did, you want to know where is the nearest library that holds one of these beauties. And not only that, but you can finally know where to go if you want to check several copies, just in case you want to compare and collate them to make sure you have not missed anything due to the good-for-nothingness of lazy scribes.
Rest assured: by the time you are done with this blog, you will know exactly where to find an early medieval manuscript of the Etymologiae and much more!
Today, we know of almost 450 early medieval manuscripts that transmit Isidore’s handy encyclopaedia in its entirety or parts of it. To be more precise, the number of surviving and identified medieval manuscripts with this text stands at the moment at 447 and continues to grow. Because of the complicated life that the early medieval manuscripts tend to lead, these 447 early medieval entities correspond to 487 modern items. Some medieval manuscripts were fragmented in modern times and are today scattered across four or five different institutions. In other cases, different manuscripts were bound together and were therefore assigned the same shelfmark.
447
Number of manuscripts
487
Number of modern shelfmarks
101
Number of locations
These 487 modern items are today deposited at 101 locations. Most of these locations are in Europe, although a handful of fragments found their way to institutions in the United States. When I write locations, I have in mind geographical places such as cities and towns, rather than institutions such as libraries, archives, or monasteries. In some cases, several different institutions in possession of early medieval copies of the Etymologiae exist at the same locations, such as in the case of various colleges at Oxford and Cambridge. I consider them a single location. There are, thus, slightly more than 101 institutions with a copy of the Etymologiae or its parts in their collections.
As can be gathered from the numbers listed above, the average number of items appearing at a single location is close to five, which may come as a surprise. In reality, this high average is a result of an extremely uneven distribution of early medieval manuscripts of Isidore’s encyclopaedia in modern manuscript-holding institutions. At 42 of the 101 locations, you can find only one manuscript, and at 18 additional locations two manuscripts of Isidore’s magnum opus. At the same time, there are 24 locations, at which you can find today at least five early medieval manuscripts of the Etymologiae and nine locations where there are at least 10 manuscripts. Among the heavy-weights with ten or more manuscript items in their collections are the Staatsbibliothek in Berlin (17 identified items), Burgerbibliothek in Bern (18 identified items), the monastery of San Lorenzo in El Escorial (10 identified items), the University Library in Leiden (15 identified items), the British Library in London (15 identified items), the Bayerische Staatsbibliothek in Munich (28 identified items), and the Stiftsbibliothek of St. Gallen (29 identified items). However, the two ultimate super-holders are the Biblioteca Apostolica Vaticana (40 identified items) and the Bibliothèque Nationale de France in Paris (90 identified items).
The numbers of the early medieval copies of the Etymologiae reflect, rather unsurprisingly, the overall holdings of early medieval manuscripts across the largest manuscript-preserving institutions in the world. The Vatican Library is the largest holder of Western manuscripts, followed by the BnF in Paris, the British Library in London, the Bayerische Staatsbibliothek in Munich and the Staatsbibliothek in Berlin. The Stiftsbibliothek in St. Gallen is perhaps not as significant in terms of its total holdings, but it is famous for the size and the integrity of its early medieval holdings, as is the University Library in Leiden. Nevertheless, the relative differences in the numbers of identified items in these five libraries are noteworthy and relevant. In particular, the difference between the number of items in the BAV (40) and BnF (90) is striking. It begs for an explanation, as one might expect to find more or just as many early medieval witnesses of work as widely diffused as the Etymologiae in the Vatican as in Paris.
The disparity has several explanations. In the first place, the Western manuscripts in the Vatican Library have not yet been fully catalogued, which means that in the case of thousands of medieval books in its vaults, we don’t have a clear idea what is in them. This is particularly true for manuscripts that could be classified as miscellanies, handbooks, and collections as well as for fragment dossiers and fragments bound in with other texts, types of medieval textual entities that usually give researchers the most trouble. If there are ‘only’ 40 known early medieval items containing the Etymologiae from this collection, it is most likely not because there are no additional early medieval manuscripts in possession of the BAV, but because they have not yet been identified. The Western manuscripts of the Bibliothèque National have similarly not been yet fully catalogued according to modern standards. Still, Paris is substantially ahead of the Vatican in this department, and especially the early medieval material is relatively well-charted. If then, 90 items corresponding to early medieval manuscripts of the Etymologiae are in the BnF, we can be reasonably sure that the BnF owns not much more than these 90 items. By contrast, we must imagine that behind those 40 identified items in the BAV are more than just a few items that were not yet identified. How many unidentified early medieval manuscripts and manuscript fragments transmitting the Etymologiae should we think are in the Vatican Library awaiting identification can be guessed from the number of the items in Paris. Even if we adjust for the differences in the histories of the respective manuscript collections and their distinct geographical scope, it is reasonable to assume that perhaps 20-30 early medieval manuscripts of the Etymologiae in the Vatican Library need to be rediscovered.

It is not just the Vatican Library that holds early medieval manuscripts (of the Etymologiae) that escape our attention. There are other institutions which we should suspect own early medieval witnesses of Isidore’s encyclopaedia, but which do not feature on my map because their collections have not been sufficiently catalogued, their catalogues are outdated, or they do not provide information of necessary granularity. Besides the Vatican, another exemplary black hole is the Biblioteca capitulare of Verona. This institution is famous for its late antique and early medieval manuscripts, but there seems not to be a single witness of the Etymologiae in this library. There are at least three manuscripts mentioned on its website that may contain material from the Etymologiae but require further probing. Another black hole is the Biblioteca Medicea Laurenziana in Florence, whose most recent complete catalogue dates from the 18th century. While the manuscript survey used to generate the map above contains two items from this institution, given the size of its collection of Western manuscripts, it seems most likely that there should be at least a few more items that were not identified.
Overall, the surveyed manuscripts allow to identify Italian institutions as a weak spot when it comes to the identification of manuscripts transmitting the Etymologiae selectively and as fragments. Crucially, roughly as many early medieval codices of the complete Etymologiae survive from German as from Italian scriptoria, and they are also similarly distributed today in German and Italian institutions. There are, however, roughly twice as many identified early medieval manuscripts transmitting parts of the Etymologiae in German institutions than in Italian ones. It is, naturally, possible to attribute some of this disparity to both differences in medieval production and uneven survival rates of manuscripts from particular regions, as reflected in the regions of their current preservation. Still, to my mind, the chief factor here is that the Italian collections were studied to a more limited extent than those from Germany. It is, in fact, clear that we need to thank Bernhard Bischoff for our current excellent state of knowledge of specific German collections of early medieval material, for he seemed to have not left a stone unturned in Germany. Here, his knowledge, connection and reputation helped him the most, and he seemed to have been able to access material that was otherwise beyond the reach of most researchers. As a result, Bischoff’s Katalog sometimes identifies early medieval material that is unknown even to the stewards of the respective collections. Bischoff, for example, writes of 14 folia of a palimpsest of the Etymologiae in the Staatsarchiv in Solothurn, which was unknown to the local archivists until the moment your humble narrator contacted them a few months ago. Overall, one can note that either an unusually high number of early medieval manuscript fragments of the Etymologiae surviving in small libraries and archives in German-speaking area as recorded in Bischoff’s Katalog, or, what is more likely, Bernhard Bischoff was in a unique position with regards to this material, and we lack the French, Italian, Spanish and perhaps even British Bischoffs who could similarly uncover fragments in small institutions in France, Italy, Spain and Great Britain.

Apart from Italy, there are several other regions and locations where one could look for early medieval manuscripts transmitting the material from the Etymologiae but will find a hole in the record. Spain is one such black hole, both because it was not covered by Bischoff in his Katalog and because many smaller institutions in Spain are still a terra incognita, especially for researchers from outside Spain. More than in the case of Italian institutions, the absence of early medieval manuscripts containing the text of the great Spanish bishop is undoubtedly also due to the relatively low survival rate of early medieval material from the Iberian peninsula. I would likewise advise anyone who seeks unidentified early medieval copies of the Etymologiae to visit the National Library in St. Petersburg.

To conclude, this blog hopefully brings home that any attempt at mapping the locations of manuscripts is also an exercise in understanding how particular collections took shape, what is their historical and political Sitz in Leben, how were they managed in the past as well as today, and to what extent they are accessible to scholars and therefore mappable and mapped. The example of Bernhard Bischoff shows that even a single (prolific) scholar can have a significant impact on what part of the mappable body of medieval material we see and therefore we may accord more significance to than we would if the body of material was uniformly mapped. We must above all avoid the naïve assumption that the manuscript material as we see it (as individual researchers) represented the body of manuscripts accurately as it existed in the period when it was produced and actively used. Too often, this is tacitly assumed. Not only is our point of view distorted by the uneven loss of manuscripts (remember, perhaps as little as 5 % of manuscripts produced in the ninth century survived). It is also distorted by the uneven quality of manuscript descriptions, the limits of our personal access, and the horizons of our ever-limited knowledge (which determines where are we going to seek information).
Any manuscript corpus such as my survey of the early medieval manuscripts of the Etymologiae is extremely sensitive to the quality of library catalogues, handlists, scholarly studies, editions, and online repositories on which it relies, amplifying their strengths and weaknesses. This needs to be understood and accounted for in any corpus-based research. I can say that this mapping exercise helped me, as I can better see where the terrain is uncharted and therefore where I need to dig further (the Vatican, Verona, St. Petersburg, northern Spain). It also revealed which collections are truly extraordinary in the number of items they amassed (Paris, where I need to return to study further those precious 90 items) and where to look for fragments. Above all, it confirmed to me how extraordinary a scholar Bernhard Bischoff was and how much he single-handedly altered our perception of the early medieval manuscript culture.

Váš najskromnejší rozprávač sa s vami dnes chce podeliť s malou novinkou: tento mesiac vychádza v slovenčina kniha, na ktorej sa autorsky podieľal. Ide o Epidémie v dejinách z dielne redakcie HistoryWebu. O čom táto kniha je asi samovravné.

Váš najskromnejší rozprávač prispel do tohoto titulu troma článkami. Dva z nich sú venované starším epidémiam a ich úlohe pri rozpade Rímskej ríše. V treťom článku sa dozviete niečo o tom, ako vznikol typicky morový kostým s vtáčím zobákom a kto ho vlastne nosil. Celkovo v knihe Epidémie v dejinách nájdete 35 článkov venovaných epidémiam od praveku až po 20. storočie. Stretnete sa so starými známymi akými sú bubonický mor, cholera, týfus, hepatitída, malária alebo Španielska chrípka, no tiež s niektorými menej známymi dejinnými aktérmi, akými boli rôzne hemoragické horúčky.
Pokiaľ vás úloha patogénov na chod dejín zaujíma, knihu si môžete objednať tu.
At the end of April 2020, the Innovating Knowledge project has silently reached the end of its second year. In normal circumstances, there would be one more year to go. However, in the altered circumstances of the corona crisis, it is evident that the project will be expanded by at least a few months. How much extra time is the project going to need will depend on when fieldwork abroad can be resumed. It is still unclear what it will mean for the health of the project and the timeline of planned outputs. It is fitting that this is the first piece of news that appears in this blog post. But now, let’s have a look at how the project has been faring in the last year.
The project’s most significant move forward was the progress in the development of the project database, which is to serve as an interactive manuscript catalogue of the pre-1000 manuscripts transmitting the Etymologiae as well as a research tool allowing for visualization of some of the most important innovations of these manuscripts. About a year ago, I reached the end of what I called ‘stage 1’ in the database development, meaning that I cleaned and enriched my original data source (Anspach’s 1940s handlist of the manuscripts of the Etymologiae) using the two key catalogues of pre-900 manuscripts (Bischoff’s Katalog and Lowe’s CLA). At the end of April 2019, the database contained, as a result, ~ 380 items (up from Anspach’s ~ 300 items). I commenced what I called ‘stage 2’ of the development, improving the data formalization model, further cleaning and enriching the data, and gathering new data from lesser sources and in-person examinations. At the end of ‘stage 2’, I hoped to have the basic component of the database ready for publication and testing. I am glad to say that ‘stage 2’ was completed at the end of March 2020. The ‘mastersheet’ now contains ~ 440 items and reached a satisfactory form. Naturally, they may be some latecomers added to the manuscript corpus. Also, there is undoubtedly a lot to check, correct and clean, not to speak of the fact that I have not been able to examine 30-40 manuscripts, which now have been itemized in the database, but for which little to no data is available. For now, however, the ‘mastersheet’ is good to go. My main goals now are to have a testable beta-version of the core database component online and to commence ‘stage 3’, which will add a new data layer to the core database component.
This being said, I have hoped for several months to see the ‘mastersheet’ online in a form that allows for basic operations (visualization, searching, filtering, download, linking to external resources). I have been assured by my manager of our institute’s digital infrastructure that a beta-version with basic functionality can be online in January. Still, there has so far been no sight of it, and even now, in May 2020, it seems to be in development. My plan has been to delegate the development of the database interface to a specialist service-provider (so that I can devote myself to research and to other project tasks and since my coding skills are minimal and I could not hope to produce anything acceptable unless it would take 100% of my time). Now, this decision is a source of immense but unavoidable frustration. To tell you the truth, I will be happy if I see the core component (aka the interactive manuscript catalogue) online eventually. I am slowly resigning on the idea of seeing any of the other components (aka the visualization tools). You will surely hear more from me about the database development soon.
Many pitfalls and frustrations notwithstanding, the database development already proved to fuel the project. It led me to make important realizations about the nature of the object studied – the manuscripts of the Etymologiae. I can now see that I need to draw lines between manuscripts transmitting the canonical Etymologiae, the various non-canonical formats of this text, which are so abundant in the early Middle Ages but badly understudied, and the fragments, which must be treated as objects sui generis. I can see that ‘innovation’ has a different meaning in the case of each of the three categories of material, requiring them to be separated for further analysis.
Another big step forward since last year concerns the digital edition of glosses to the first book of the Etymologiae. I have now transcribed glosses from all 25 core manuscript witnesses as well as from additional 37 manuscripts. This means that the raw material is more or less ready. Now is the high time to start encoding these glosses in XML (with the help of my great colleague Peter Boot who prepared a TEI schema for me!). I would wish to be busying away encoding right now but have fallen behind terribly since the beginning of 2020. I am now at least several months delayed and thus worried about producing presentable outputs (the edition). I sincerely hope I will be able to catch up on editing very soon thanks to the corona lockdown.
I can see that since last year, I have been on ten field trips, bringing the total of visited libraries to about 20. Some of the most satisfying of these trips was a visit to the Staatsbibliothek in Berlin (May 2019) and a visit to the Biblioteca Apostolica Vaticana (November 2019). There are still almost 40 libraries left that own manuscripts which are not described satisfactorily and thus require personal inspection. It is obvious that I can visit only a handful of them. The top priority are libraries in northern Italy, Spain, Bavaria and Switzerland, as well as returning to Paris and the Vatican for another dip. In fact, I was planning to be in Italy in April and in Germany and Switzerland in May but had to scrap my plans due to the pandemic. I hope that the few months of extension I can ask for will be enough to make up for the unwanted hiatus in 2020 and perhaps some libraries will take it as a cue to speed up the digitization of their manuscript collections.
Given that about a year ago, I had only one project-related article submitted (and it is still not out), it is really satisfying to see that I was able to move on the project publications. I have successfully submitted my first case study as a license for medieval studies thesis in June 2019. I am now about to send it off to a journal (still requires some editing). A book review for Fragmentology is out since the end of 2019. I have also submitted a survey article, the first fruit of the database-powered research, in February this year. I am currently finishing an article about the materiality of the early manuscripts of the Etymologiae as a crucial pathway for innovations, which should be ready to go by the end of May. There are still several draft articles on my desk and a few more good article ideas in my mental drawer. I don’t know how many of them will I be able to submit while the project is running, or how many I will be able to finish at all. Still, my hopes are high, mostly because of how great the project data are. At times, one feels the articles are begging to be written.
I have published a call for papers for my end-project conference in February. Because of the current crisis, it is a big mystery whether it can take place physically in October as planned. Since I received more abstracts than I could accommodate speakers at the conference, making the conference digital may be an excellent opportunity to keep as many of them as possible. I see it as a call to experiment with the traditional conference format, which is not always satisfactory anyways. Any tips for how to manage a conference in the corona times are welcomed!
In the Autumn of 2019, I have also had my first project intern, a master student from Utrecht University who wrote her seminar paper about my manuscripts under my supervision. I hope it was just as useful experience for her as it was for me. Since she is probably the only intern I will have, the three months we spent meeting weekly to learn about the early medieval fragments of the Etymologiae are particularly dear to me. Thanks to her, I was inspired to revisit the question of fragments, their transmission and their importance as a test group for non-fragmentary preserved material. I have acquired images of 63 of the 78 items in my corpus that are fragments (and a few more are hopefully underway) in the hope that at least some of them can end on the Fragmentarium website. It is now more than a year since I talked with members of the Fragmentarium team about this option and I am a bit ashamed I have not moved much in this respect. I still have hope that the fragments can appear on Fragmentarium someday, although maybe not many of them and not until the very end of the project.
Last but not least, I have engaged in a lot of scientific communication about the project. In June 2019, I spoke about my project at a NerdNite in Bratislava. In November 2019, I participated in a triple-talk tour as a part of Slovak Week of Science. I was also interviewed for a podcast and for a radio show. In October last year, I organized a talk about the copyright issues connected with the ongoing digitization of historical collections. And the most fabulous update of all is that this website is up!
Looking back at what I was able to achieve in the course of the last twelve months makes me feel both happy and frustrated. I can see that the project is finally starting to take a definitive shape (and looks quite different from how I envisaged it when I submitted my grant application). It is generating first presentable results that are on their way to the press. However, I can also see that I am trying to do too many things in too short a time. I knew I was doing too much when I was starting this project in 2018. I thought that many ideas would wither away on their own, allowing me to stay focused on the few best ones. Yet, two years later, I can see I have not discarded enough ideas. I am clinging to too many exciting directions, juggling the database, the edition, the project publications, the research trips, the project conference, and a (still only potential) collaboration with the Fragmentarium. I have always had a hard time to drop down projects. I feel that in this way, I am doing a disservice to my project. If there were fewer sub-projects tied in, they would be closer to completion.
If you have any tips or comments stemming from this report, let me know!
The ‘Innovating Knowledge’ Project is calling for submissions for an international conference to be held on
22-23 October 2020
at Huygens ING, Amsterdam


In the last decade, methods of network analysis developed by social scientists have been increasingly applied to historical disciplines. As a result, we have seen the emergence of new bodies of researchers working with network analytical methods, such as Social Network Analysis Research in the Middle Ages (SNARMA), and new journals, such as the Journal of Historical Network Research (JHNR). Researchers studying premodern manuscript cultures have been actively engaged with this new methodological trend. Completed and ongoing projects make it clear that the methods of network analysis can be applied to the study of premodern manuscripts and manuscript texts and yield relevant and exciting results. However, it is also clear that scholars of premodern written cultures face unique challenges when engaging with network analysis stemming from the nature of the material they are working with. Not all methods devised by social scientists are applicable to manuscripts and texts, while in other cases, established methods need to be adapted to and reinvented for new needs. Working with large corpora of manuscripts and texts, and approaching premodern written cultures from a quantitative perspective bring their unique challenges to fields that have a long tradition of looking at their subjects in small quantities and with a qualitative lens. As any young methodological subfield, the study of premodern manuscripts and manuscript texts using network analysis is still in an exploratory stage, with theoretical frameworks being forged and methods tested.
This conference aims to bring together researchers applying network analysis to premodern manuscripts and manuscript texts. We would like to invite researchers working in all fields of premodern manuscript studies and researchers working with manuscript texts who engage with the methods and concepts stemming from network analysis. Key topics include, but are not limited to, the following:
We welcome proposals in two categories: a) 30- minute full papers suitable for presenting completed or ongoing research; and b) 20-minute exploratory papers suitable for presenting newly started research or research proposals that are still being developed. The second category is particularly intended for early career researchers who are new to the field of network analysis and wish to have their ideas tested in front of an expert audience.
A keynote by Matteo Valleriani (Max Planck Institute for the History of Science, Berlin/Technische Universität Berlin/University of Tel Aviv) is included on the first day of the conference.
Proposals of between 300 and 500 words should be sent to Dr Evina Steinová at evina.steinova@gmail.com by the end of April 2020. Authors of successful submissions will be informed by the end of June 2020 and encouraged to submit full papers in the following months so that they can be circulated in advance to stimulate a fruitful discussion.
The language of the conference will be English. We offer to cover the accommodation costs for two nights and provide lunches. We also intend to provide a small number of bursaries to speakers who may need travel assistance.
For further information, contact Dr Evina Steinová at evina.steinova@gmail.com.
You can download this call for paper here.














